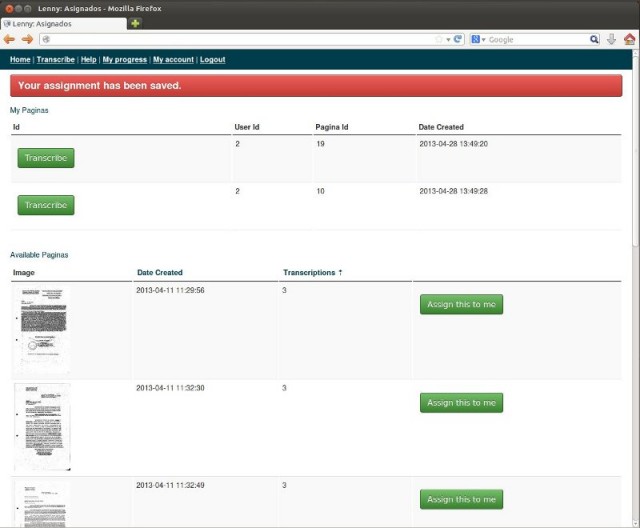
For my master’s report, I developed a workflow for transcribing large collections of scanned documents. The process begins by segmenting scanned documents into words of individual images (see Figure 1).

Then I developed a crowdsourcing web application using CakePHP to allow volunteers to transcribe a portion of the words (see Figures 2 and 3).
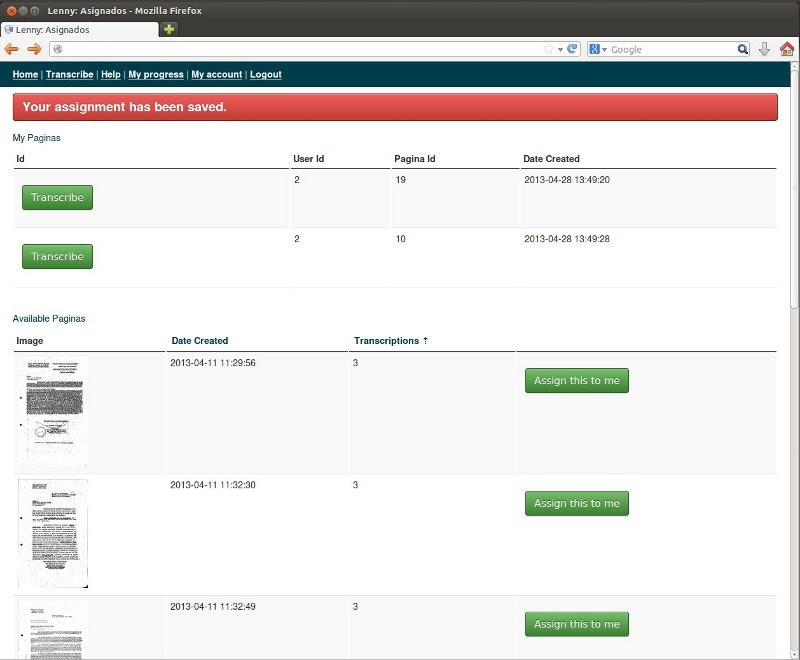
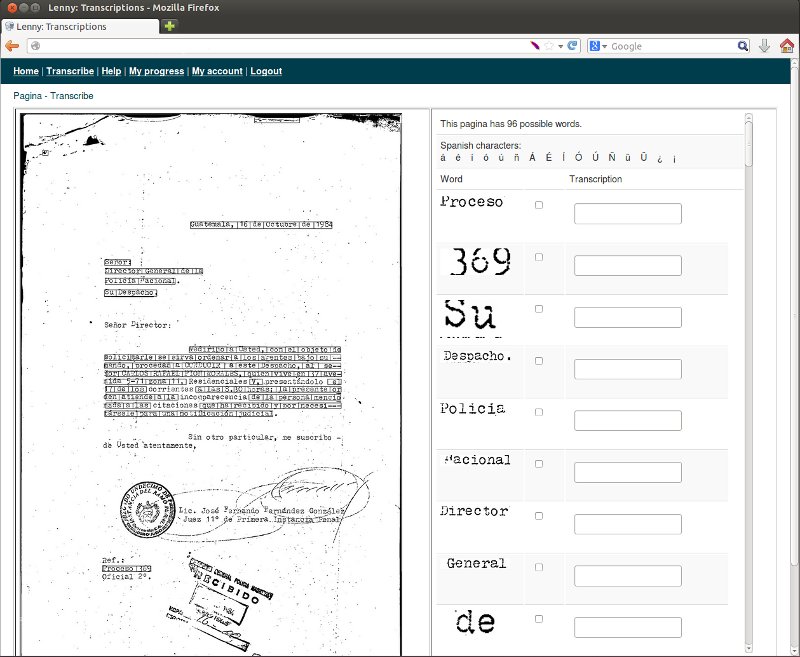
Finally, I used the OpenCV libraries to match images of words by comparing their sizes, histograms and keypoint descriptors obtained with the SURF algorithm (See Figure 4). If the images matched, the text obtained from crowdsourcing is associated with the new image of a word.





